业务使用布隆过滤器的最佳实践分析:以Redis实现为例
- 一、布隆过滤器核心原理
- 二、Redis Bloom模块:高效实现方案
- 三、最佳业务实践场景分析
- 1.缓存穿透防护(高频刚需)
- 2.推荐系统去重
- 3.邮件垃圾过滤系统
- 4.URL爬虫去重
- 四、关键参数配置与性能优化
- 1. 容量规划与错误率
- 2. 错误率公式速查
- 3. 弹性扩展实践
- 五、生产环境使用建议
- 六、总结:收益与风险并存的技术选型
在互联网业务高速发展的今天,面对海量数据的存储与查询,如何在保障系统性能的同时提升查询效率成为关键挑战。布隆过滤器(Bloom Filter)作为一种空间效率极高的概率型数据结构,因其在应对大规模数据判定问题时卓越的节省空间能力而备受瞩目。本文将深入探讨Redis实现的布隆过滤器原理,并通过实际业务场景解析其最佳实践方案。
一、布隆过滤器核心原理
问题核心: 如何高效判断一个元素是否存在于超大规模集合中?
传统方案痛点: 使用HashSet或数据库存储时,内存/磁盘开销极高,查询速度随数据增长而下降。
布隆过滤器解决方案: 使用一个超大的二进制位数组(Bitmap) 配合多个哈希函数,以少量空间与可控的错误率(假阳性)为代价,换取极高的空间效率和查询速度。
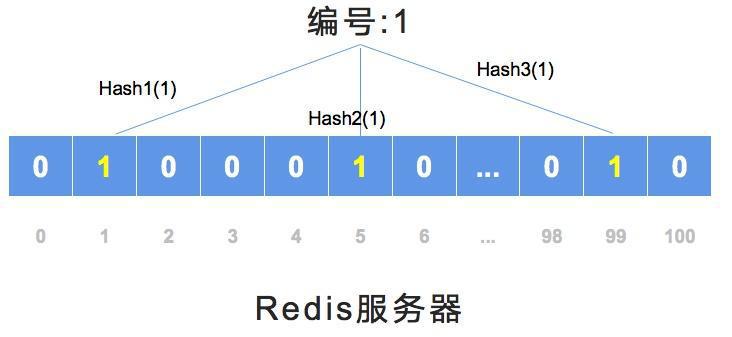
图示说明:元素经多个哈希函数映射到位数组对应位置并置为1;定时若所有位置均为1则视为可能存在,任一位置为0则必然不存在
二、Redis Bloom模块:高效实现方案
Redis自4.0版本起通过插件(RedisBloom)支持原生存布隆过滤器操作,核心优势如下:
# RedisBloom基本操作命令
BF.ADD users:filter "user123" # 添加元素
BF.EXISTS users:filter "user123" # 检查存在性
BF.MADD ... # 批量添加
BF.RESERVE myfilter 0.01 1000000 # 初始化过滤器:错误率0.01, 容量100万
底层数据结构: Redis使用一个String类型存储位数组(自动扩展),并通过高效哈希函数计算位偏移量。
Redis通过String存储二进制位,哈希函数将输入元素映射到多个位位置。
三、最佳业务实践场景分析
1.缓存穿透防护(高频刚需)
痛点: 大量请求查询缓存和DB都不存在的Key,导致数据库压力激增。
解决方案: 前置布隆过滤器拦截非法Key。
python
defget_data(key):
ifnot redis_bloom.exists('valid_keys', key):
returnNone# 快速拦截非法Key
data = cache.get(key)
if data isNone:
data = db.get(key)
cache.set(key, data, timeout=300)
return data
业务价值: 某电商平台拦截99.8%的无效商品ID查询,数据库QPS下降90%。
2.推荐系统去重
场景: 用户已读内容过滤,避免重复推荐。
方案: 使用BF.ADD记录用户历史行为ID集合。
BF.MADD user:100:history "news_456" "video_789" "post_101"
性能优势: 存储1亿历史记录仅需约100MB内存 (0.1%误判率),远低于数据库索引。
3.邮件垃圾过滤系统
需求: 快速判定发件地址是否在黑名单中。
方案: 分布式BF集群存储已知垃圾邮件地址。
java
publicbooleanisSpamEmail(String email) {
return redis.bloomExists("spam:emails", email);
}
效果: 百万级黑名单过滤响应时间<1ms,同时节省90%的KV存储空间。
4.URL爬虫去重
挑战: 快速判断URL是否已被抓取。
Redis方案:
BF.ADD crawled_urls "https://www.abc.com/page1"
扩展性: 支持动态扩容,满足百亿级URL管理需求。
四、关键参数配置与性能优化
1. 容量规划与错误率
| 预期元素数量 | 误判率 | 位数组大小 | 哈希函数数量 |
|---|---|---|---|
| 1,000,000 | 0.1% | 1.71MB | 7 |
| 10,000,000 | 0.01% | 19.55MB | 14 |
# 推荐初始化配置 BF.RESERVEmyfilter 0.001 5000000
2. 错误率公式速查
ϵ≈(1−e−kn/m)k
其中 m=位数组大小, n=元素数量, k=哈希函数数
3. 弹性扩展实践
- 通过SCALING参数启动自动扩容:BF.RESERVE ... SCALING 1
- 监控错误率变化,超过阈值触发重建
五、生产环境使用建议
-
严格规避删除操作
标准BF不支持删除(导致误删)。需删除时切换至计数布隆过滤器(Cuckoo Filter)。 -
灾难恢复机制
定期备份位数组状态(DUMP),故障时通过RESTORE重建。 -
监控指标预警
# 监控关键指标 bf.memory_usage myfilter # 内存占用 bf.error_rate myfilter # 实测误判率
-
分布式场景协同
超大容量需求时采用分片方案:shard_id = crc32(key) % SHARD_COUNT filter_key = f'bf_shard_{shard_id}'
六、总结:收益与风险并存的技术选型
核心收益:
内存消耗仅为传统方案的1%~10%
查询性能稳定在O(k),亿级数据毫秒响应
适用于分布式系统大规模数据判定
使用前提:
不适用于要求100%精确的场景(金融交易校验等)
需容忍预设可控的错误率
不支持元素删除(标准版本)
布隆过滤器凭借独特的时空效率,已成为高并发、大数据量业务场景的基础设施之一。结合Redis的生态支持,开发者可快速构建抗海量流量的防护与过滤中间件。
记得有位技术架构师所言:在分布式系统的‘工具箱’里,布隆过滤器就是那把精确度稍逊却削铁如泥的苗刀,关键看你会不会用。
评论
发表评论
|
|
|